
胡安·曼纽尔·奥尔蒂斯·德·萨拉特
验证专家 in 工程
Juan是一名开发人员, 数据科学家, 他是布宜诺斯艾利斯大学研究社交网络的博士研究员, AI, 和NLP. Juan拥有十多年的数据科学经验,并在ML会议上发表过论文, 包括SPIRE和ICCS.
以前在

Juan是一名开发人员, 数据科学家, 他是布宜诺斯艾利斯大学研究社交网络的博士研究员, AI, 和NLP. Juan拥有十多年的数据科学经验,并在ML会议上发表过论文, 包括SPIRE和ICCS.
本文是关于使用R和推特聚类分析的三部分系列文章的最后一部分 Gephi. 第一部分 分析网络热议 关于著名的阿根廷足球运动员 Lionel Messi; part two 加深分析 更好地识别主要行为者,了解话题传播.
政治两极分化. 当我们发现有趣的群体有着截然不同的观点, 从这些阵营中产生的推特消息往往密集地集中在两组用户周围, 它们之间有一点联系. 这种类型的分组和关系称为 同质性与与我们相似的人互动的倾向.
在 前一篇文章 在本系列中, 我们专注于基于推特数据集的计算技术,并能够通过 Gephi. 现在我们要用 聚类分析 为了理解我们可以从这些技术中得出的结论,并确定哪些社会数据方面是最有信息的.
我们将改变分析的数据类型,以突出这种聚类, 从5月10日开始下载美国的政治数据, 2020, 到5月20日, 2020. 我们将使用与中相同的推特数据下载过程 第一篇文章 在本系列中,将下载标准从“梅西”改为“时任总统的名字”.”
The following figure depicts the interaction graph of the political discussion; as we did in the 第一篇文章, 我们使用ForceAtlas2布局与Gephi绘制了这些数据,并通过Louvain检测到的社区着色.

让我们深入研究一下现有的数据.
正如我们在本系列中所讨论的那样, 我们可以通过它们的权威来描述集群, 但推特给了我们更多可以分析的数据. 例如,用户描述字段,推特用户可以在其中提供简短的自传. 使用词云,我们可以发现用户是如何描述自己的. 这段代码基于在每个集群的描述中发现的数据中的词频生成两个词云,并突出显示人们的自我描述如何以聚合方式提供信息:
#加载必要的库
库(rtweet)
库(igraph)
库(tidyverse)
库(wordcloud)
库(tidyverse)
库(NLP)
库(tm)
库(RColorBrewer)
#首先,通过鲁汶确定社区
my.com.快速= cluster_louvain(as.无向(简化(净)),分辨率= 0.4)
#下一步,获取符合两个最大集群的用户
largestCommunities <- order(sizes(my.com.快),减少= TRUE) [1:4]
社区1 <- names(which(membership(my.com.== largestCommunities[1]))
社区2 <- names(which(membership(my.com.== largestCommunities[2]))
#现在,将推文的数据帧按社区拆分
# (i.e.“共和党”和“民主党”)
共和党=推特.df ((tweet.Df $screen_name %in% 社区1),]
民主党=推特.df ((tweet.Df $screen_name %in% 社区2),]
#下一步,假设我们每条推文有一行,我们想分析用户,
让我们只保留一行用户
Accounts_r = republicans[!复制(共和党[c (screen_name)]),)
Accounts_d = democrats[!复制(民主党[c (screen_name)]),)
#最后,通过聚类绘制用户描述的词云
##生成共和党词云
首先,将描述转换为tm语料库
corpus <- Corpus(VectorSource(unique(accounts_r$description)))
删除英文停顿词
corpus <- tm_map(corpus, removeWords, stopwords("en"))
###删除数字,因为它们在这一步没有意义
corpus <- tm_map(corpus, removeNumbers)
绘制显示最多30个单词的单词云
同时,过滤掉只出现一次的单词
pal <- brewer.“Dark2”pal(8日)
wordcloud(语料库,分钟.频率= 2,马克斯.单词= 30,随机.order = TRUE, col = pal)
##生成民主党词云
corpus <- Corpus(VectorSource(unique(accounts_d$description)))
corpus <- tm_map(corpus, removeWords, stopwords("en"))
pal <- brewer.“Dark2”pal(8日)
wordcloud(语料库,分钟.频率= 2,马克斯.单词= 30,随机.order = TRUE, col = pal)
以往美国大选的数据揭示了这一点 选民在地理区域上是高度隔离的. 让我们深化身份分析,关注另一个领域:place_name, 用户可以提供居住地的字段. 这 R 代码基于这个字段生成词云:
# Convert place names to tm corpus corpus <- Corpus(VectorSource(accounts_d[!is.na (accounts_d place_name美元)]place_name美元))
删除英语停顿词
corpus <- tm_map(corpus, removeWords, stopwords("en"))
#删除数字
corpus <- tm_map(corpus, removeNumbers)
#地块
pal <- brewer.“Dark2”pal(8日)
wordcloud(语料库,分钟.频率= 2,马克斯.单词= 30,随机.order = TRUE, col = pal)
##对accounts_r执行同样的操作

一些地方的名字可能同时出现在两个词云中,因为两党的选民都居住在大多数地方. 但是有些州, 像德克萨斯, 科罗拉多州, 俄克拉何马州, 和印第安纳州, 强烈代表共和党,而一些城市, 比如纽约, 旧金山, 和费城, 与民主党密切相关.
让我们来探索数据的另一个方面, 关注用户行为并检查每个集群中创建帐户的时间分布. 如果创建日期与集群没有关联, 我们将看到每天用户的均匀分布.
让我们画一个分布的直方图:
#首先,我们需要格式化帐户日期字段,以便有效地读取日期
注意,我们使用的是accounts_r和accounts_d数据帧, 这是因为我们希望关注唯一的用户,而不是通过每个用户提交的tweet数量来扭曲情节
accounts_r$date_account <- as.(截止日期(格式.POSIXct (accounts_r account_created_at美元,格式= ' % Y - % m - H % d %: % m: % S '),格式= Y % - % - % d '))
现在我们绘制直方图
ggplot (accounts_r, Aes (date_account)) + geom_histogram(stat="count")+scale_x_date(date_breaks =" 1 year"), date_labels = "%b %Y")
##对accounts_d做同样的操作

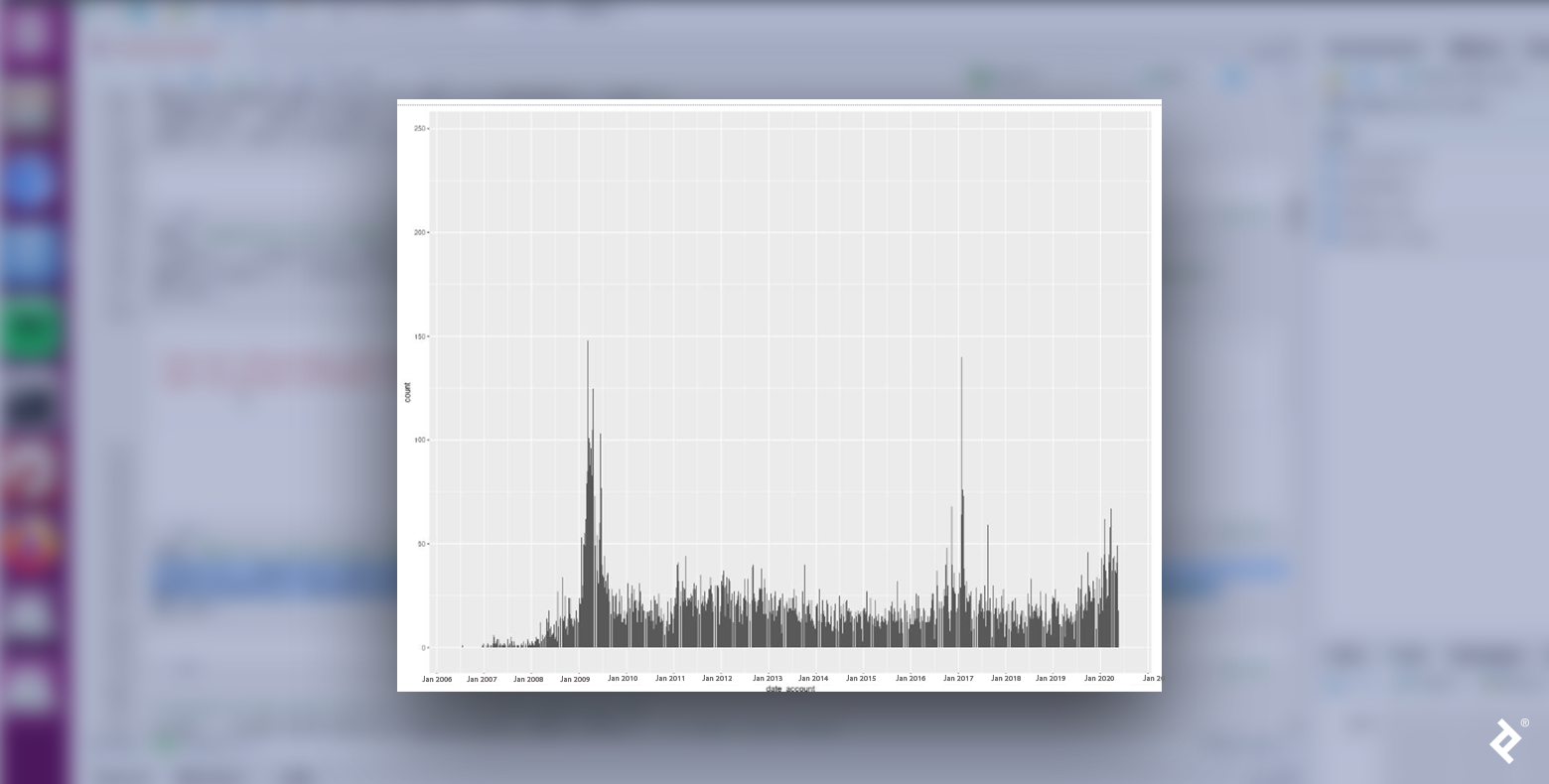
我们看到,共和党和民主党用户的分布并不均匀. 这两种情况, 新用户账户数量在2009年1月和2017年1月达到峰值, 这两个月都是前几年11月总统选举后举行就职典礼的月份. 会不会是这些事件的临近导致了政治承诺的增加? 这是有道理的,因为我们正在分析政治推文.
同样值得注意的是:共和党数据中最大的峰值出现在2019年中期之后, 在2020年初达到最高点. 这种行为上的变化是否与疫情带来的数字习惯有关?
民主党的数据在此期间也出现了峰值,但数值较低. 也许共和党支持者表现出更高的峰值,因为他们对COVID封锁有更强烈的看法? 我们需要更多地依靠政治知识, 理论, 和发现来发展更好的假设, 但不管, 我们可以从政治角度分析一些有趣的数据趋势.
另一种比较行为的方法是分析用户如何 转发和回复. 当用户转发时, they sp读 a message; however, 当他们回复时, 它们有助于特定的对话或辩论. 通常, 回复的数量与推文的分裂程度有关, 不受欢迎, or controversy; a user who 最喜欢的 a tweet indicates agreement with the sentiment. 让我们来看看 率测量 之间的 最喜欢的 和 回复 一条微博.
基于同质性,我们期望用户转发来自同一社区的用户. 我们可以用R来验证:
#获取双方都转发过的用户
Rt_d = democrats[哪一个]!is.na(民主党retweet_screen_name美元)))
Rt_r = Rt_r = Rt_r!is.na(共和党retweet_screen_name美元)))
#从民主党到共和党的转发
Rt_d_unique = rt_d[!复制(rt_d [c (retweet_screen_name)]),)
Rt_dem_to_rep = dim(rt_d_unique[which(rt_d_unique$retweet_screen_name %in% unique(republicans$screen_name))),])[1] /暗(rt_d_unique) [1]
#民主党人对民主党人的转发
Rt_dem_to_dem = dim(rt_d_unique[which(rt_d_unique$retweet_screen_name %in% unique(democrats$screen_name))),])[1] /暗(rt_d_unique) [1]
#剩余部分
Rest = 1 - rt_dem_to_dem - rt_dem_to_rep
#创建一个数据框架来制作情节
data <- data.框架(
类别= c(“民主党人”,“共和党人”,“其他”),
数= c(圆(rt_dem_to_dem * 100, 1),圆(rt_dem_to_rep * 100, 1),圆(* 100,1))
)
#计算百分比
data$fraction <- data$count / sum(data$count)
#计算累计百分比(每个矩形的顶部)
data$ymax <- cumsum(data$fraction)
#计算每个矩形的底部
data$ymin <- c(0, head(data$ymax, n=-1))
#计算标签位置
data$labelPosition <- (data$ymax + data$ymin) / 2
#计算一个好的标签
data$label <- paste0(data$category, "\n ", data$count)
#制作情节
Ggplot (data, aes(ymax=ymax, ymin=ymin, xmax=4, xmin=3, fill=c('red',“蓝”,“绿色”)) +
geom_rect () +
geom_text (x = 1, aes (y = labelPosition, 标签=标签, 颜色= c(“红”,“蓝”,“绿色”)), Size =6) + # x这里控制标签位置(内/外)
coord_polar(θ= " y ") +
Xlim (c(- 1,4)) +
theme_void () +
主题(传说.Position = "none")
#对rt_r做同样的操作

不出所料,共和党人倾向于转发其他共和党人的推文,民主党人也是如此. 让我们看看党派关系是如何应用于推特回复的.

这里出现了一个非常不同的模式. 而用户则倾向于更频繁地回复分享党派关系的人的推文, 他们仍然更有可能转发这些帖子. 也, 似乎不属于这两种主要类型的人更倾向于回复.
的主题建模技术 本系列的第二部分, 我们可以预测用户将选择与同一集群的人和相反集群的人进行什么样的对话.
下表详细介绍了每种类型的交互中讨论的两个最重要的主题:
| 民主党人对民主党人 | 民主党转向共和党 | 共和党对民主党 | 共和党人对共和党人 | ||||
| 话题1 | 话题2 | 话题1 | 话题2 | 话题1 | 话题2 | 话题1 | 话题2 |
| 假的 | 人 | 特朗普 | 美国人 | 新闻 | 拜登 | 人 | 中国。 |
| 普京 | covid | 新闻 | 特朗普 | 假的 | 奥巴马 | 钱 | 新闻 |
| 选举 | 病毒 | 假的 | 死 | 美国有线电视新闻网 | 奥巴马gate | 国家 | 人 |
| 钱 | 采取 | 谎言 | 人 | 读 | 乔 | 开放 | 媒体 |
| 特朗普 | 死 | 狐狸。 | 死亡 | 假的_新闻 | 证据 | 回来 | 假的 |
当我们数据集中的用户回复时,假新闻似乎是一个热门话题. 不管用户的党派关系如何, 当他们回复对方的时候, 他们谈论的是他们所在政党的人通常喜欢的新闻频道. 其次, 当民主党人回答其他民主党人时, 他们倾向于谈论普京, 假选举, 和COVID, 而共和党人则专注于阻止封锁和来自中国的假新闻.
两极分化是社交媒体的一种常见模式,不仅在美国,而且在世界各地都在发生. 我们已经看到了如何在两极分化的情况下分析社区身份和行为. 有了这些工具, 任何人都可以在他们感兴趣的数据集上重现聚类分析,看看出现了什么模式. 这些分析的模式和结果既可以提供教育,也可以帮助产生进一步的探索.
数据聚类识别数据集中的组.
聚类分析确定社区围绕的主题和数据维度.
同质性是人们倾向于与与自己性格和观点相匹配的人交往的原则.
同质性是指个体被具有相同人口特征和思想的人所吸引. 这些用户在使用社交媒体时也表现出这些倾向.
社交媒体数据分析可以识别用户群体关注的关键词和主题. 这些焦点可以证明这些用户的同质性.
世界级的文章,每周发一次.
世界级的文章,每周发一次.

 作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.
作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.